This is a one-man's quest on making an Open world game, with a capital-O.
It seems ages ago, that I was playing an Elder Scrolls game. It was big, and it was open.
What impressed me most about it was the following:
With a hundred settlements on the map, and dozens of houses per settlement, you canvisit any one those settlements, enter a random house, and check out its book shelves.
You could take a book from the shelves, and then, for instance, drop that book underneath a stairwell.
Then, after doing all sorts of quests, fighting legions of foes, slaying of dragons, traveling far and wide, you could return to that house.
And guess what?
That book you dropped, at what seems to be ages ago, is still there under the stairwell.
In short, there is permanence in the world. A permanence of detail.
(I remember reading that the developers did put some limits on that to cut down on the size of saved games, but in essence it did achieve this permanence.)
I thought about how to push this openness even further.
What is not possible in that particular game, but would push the amount of influence a player has on a game world?
Digging
In real life, I can dig a ditch in my yard, and even if I leave the country for a year, that ditch will still be there when I return to the yard.
Heck, even if a ditch gets filled in by erosion, or human interference, the traces of a ditch will be there two millennia later, when Time Team archaeologists excavate it looking for a Roman villa.
I don't think there are many games that let you dig a hole anywhere in the world, and have that persist.
Although, thinking about it, Minecraft would qualify.
Considering that my indie game is a one man effort, I can't create a huge authored game world.
Which means that I will, like Minecraft, rely on procedural generation of my universe.
But, after that procedural generation, I want the player to be able to dig anywhere, and everywhere.
Enter The Planetary Ring
As a setting for my game, I have chosen space.
More specifically, a whole bunch of rocks orbiting a planet.
Procedural generation using 3D noise fields are well suited to create amorphous blobs in space.
There is of course the whole problem of a 10,000 bowls of oatmeal, but still, it is easy to create a scene in which the player will experience the vastness of space.
18 billion billion
A side note here: even though the world is presented as a ring of rocks around a planet, I decided to make this ring infinite:
As the player hops from one rock to the next, I keep generating new ones at the far end, causing the player never to reach the other side of the planet.
With a 64-bit seed for each rock, 18 billion billion different rocks can be generated.
This guarantees the player will never see the same rock twice, regardless how long they travel for.
Every planetoid in the game approaches a billion cubic feet of rock. Each and every cubic foot in there, can be dug by the player.
This enables the "Tunnel To China" where you can dig to the other end of the planetoid, for instance.
To add permanence to the player's influence on this world, we have to store the modifications by the player of course.
Only that terrain that was modified by the player is stored to disk, leaving the virgin grounds represented by the proc-gen algorithm alone.
So, even though the game world is infinite, the amount of digging is limited by the disk space of the player's computer.
Generation
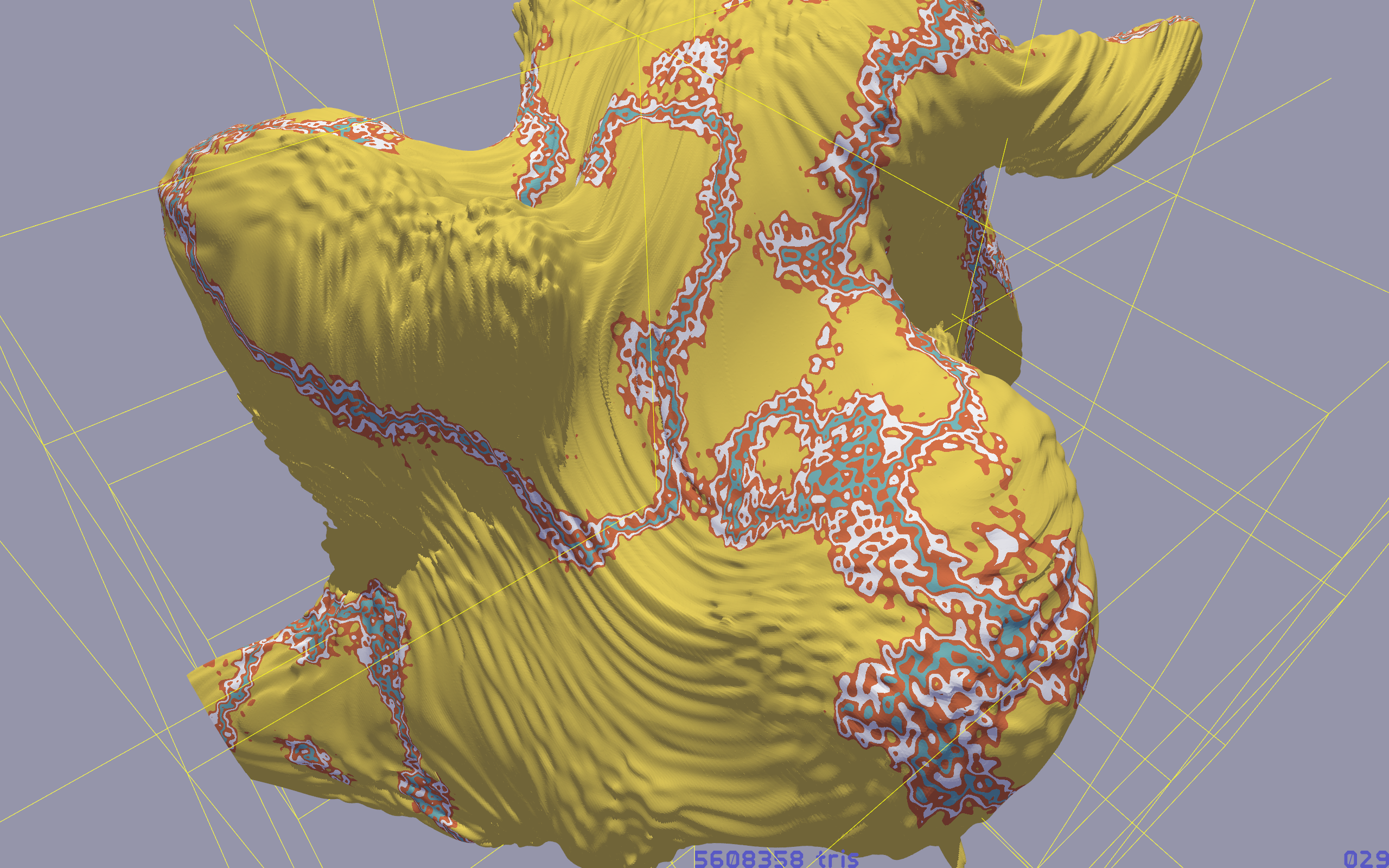
About the generation of the space rocks: they are defined by two large 3D noise fields.
One field defines the density, and by using the Marching Cubes algorithm, a surface is generated to define the shape of the object.
The other field defines the material type. This enables me to define veins of mineral ore inside the object.
Standard functions, like Open Simplex Noise, will create smooth terrains and never show steep cliffs.
To add cliffs and ragged shapes, we can employ a technique called domain warping:
Instead of sampling the noise function with straight x/y/z grid locations, the sample positions are perturbed with another noise value.
See Sean Murray's GDC presentation on noise for more info on this.
Results So Far
So, what are the results so far?
Well, that little space rover can dig holes in any rock, fly for ages to other parts of the world, and when it returns to the original space rock, those holes are still there.
Permanence achieved! Next up: gameplay.
Gameplay is of course the part that matters, but it helps if you can set it in a world where the player has a strong sense of agency. Go anywhere, and leave your permanent mark.