Shot with Ernst Leitz Epis 400mm f/4.

Shot with N.P.L. 20" Anastigmat lens.

The Ernst Leitz lens:

The N.P.L. lens:

Shot with Ernst Leitz Epis 400mm f/4.
Shot with N.P.L. 20" Anastigmat lens.
The Ernst Leitz lens:
The N.P.L. lens:
I have recently released an open source tool called sotrace. It maps out the .so dependencies for a binary or library, and presents them in a nice graph.
When I run it on my lean, mean, simple test program that runs a Vulkan Compute shader, I get this graph of dynamically linked libraries.

So tidy!
Because I also wanted run-time loaded dependencies, I added a mode where you can run sotool on a process-id instead. Running it on a process of the exact same binary, I gaze into the chasm of complexity with despair:

Sweet Mother of Isaac Newton! What is this abomination?
This runs a compute kernel on a GPU, with no graphics output at all. Why is X11 pulled in? And even some wayland stuff? Ugh. This is what I've come to see as hidden dependencies. My program depends on them, even though it does not link against them.
Meanwhile, when I use CUDA instead of Vulkan, I get serenity back. CUDA FTW!

And for completeness, when I run the OpenCL version of my compute kernel:

So, if you are a developer on Linux, give it a try and be amazed at what you dredge up. Let me know your findings!
"Yours Truly, Bram, fighting complexity wherever he finds it.
So, my Photon Mapping experiments led me from CUDA to OpenCL (for better compatibility) and now to Vulkan for even better compatiblity. OpenCL is just not cutting it anymore: abandoned by Apple, ignored by AMD. The latter I found out when I tried to use OpenCL on a mobile Ryzen iGPU under Linux: no go!
So Vulkan it is. I have always found Vulkan to be intimidating. It is just too much, before you will ever see a single triangle on your screen. I am hopeful that Vulkan Compute is less cumbersome, and it seems to be that way.
You still needs heaps and heaps of configuration and setup code, though. And I am slowly making my way through that. You can follow my progress at MinimalVulkanCompute github.
Some other sources for inspiration are Sascha Willems' example and Neil Henning's example
Vulkan uses SPIR-V modules to represent the compute kernels. So I need to port my OpenCL or CUDA code to this. I think I can just transpile my OpenCL code into SPIR-V using Google's clspv project.
After building clspv it appears that it ingests my OpenCL code pretty well, as it manages to create SPIR-V output. So far so good. I still need to execute it in my Vk code. I wonder how much performance is lost by the intermediate step, compared to a native OpenCL driver?
Next order of business is to figure out if I should create staging buffers. For an iGPU, all memory is the same. But for a dGPU, I have a lot of options for which type of memory to use. For instance, using my RX580 Radeon dGPU, I see:
$ ./minimal_vulkan_compute Found 3 physical devices. 8086:4680 iGPU Intel(R) UHD Graphics 770 (ADL-S GT1) 1002:67df dGPU AMD Radeon RX 580 Series (RADV POLARIS10) 10005:0000 CPU llvmpipe (LLVM 15.0.7, 256 bits) 7 mem types. 2 mem heaps. 4096 MiB of local memory [ device-local ] 4096 MiB of local memory [ device-local ] 15908 MiB of non-local memory [ host-visible host-coherent ] 4096 MiB of local memory [ device-local host-visible host-coherent ] 4096 MiB of local memory [ device-local host-visible host-coherent ] 15908 MiB of non-local memory [ host-visible host-coherent host-cached ] 15908 MiB of non-local memory [ host-visible host-coherent host-cached ]
I have the vulkan port finally working as it should. Some things that tripped me up: A Vulkan kernel gets the work group size from the SPIRV. Whereas an OpenCL kernel can just set it in the clEnqueueNDRangeKernel() call, at client side. This makes the clspv route a little tricky: we need to spec the workgroup size in the CL kernel source, using __attribute__((reqd_work_group_size(x, y, z)))
The end result is that the CL -> clspv -> SPIRV -> Vulkan overhead takes quite a bit of performance away. The overhead is tolerable on nvidia RTX, but it is too much on Intel:
NVIDIA GeForce RTX 3060 Laptop GPU NVIDIA Corporation with [30 units]
OPENCL:
rayt: 2953 µs
boun: 2989 µs
binp: 1458 µs
CLSPV+VULKAN:
rayt: 3543 μs
boun: 3586 μs
binp: 1224 μs
Intel(R) UHD Graphics 770 (ADL-S GT1)
OPENCL:
rayt: 22017 µs
boun: 20927 µs
binp: 7310 µs
CLSPV+VULKAN:
rayt: 44635 μs
boun: 40133 μs
binp: 8490 μs
Depending on the platform, my compute time goes up between +20% and +100% when using transpiled OpenCL kernels via clspv. I should also mention that I have found the performance difference between CUDA and OpenCL insignificant.
We have fallen for the folly of maximum GPU performance. It is the age of 450 Watt GPUs. Why is that?
There is absolutely no need to have 450 Watt GPUs. The sole reason they use that much, is for a few additional FPS in the benchmarks. For real-world use, that 450 Watt is useless, as I have come to conclude after running an experiment.
Traditionally, I have always used NVIDIA GPUs in my Linux boxes, for stability and performance. But today, I am running an (elderly) AMD RX580 in my main rig. NVIDIA on Linux does not give you much control over clock speeds and voltages, but CoreCtrl let's me adjust the clocks for the RX580.
I already knew that for the last few percent of performance, you need a heap more wattage. This is because Wattage increases linearly with clock speed, but quadratically to the Voltage. Increasing Voltage comes at a huge cost. Let's quantify that cost.
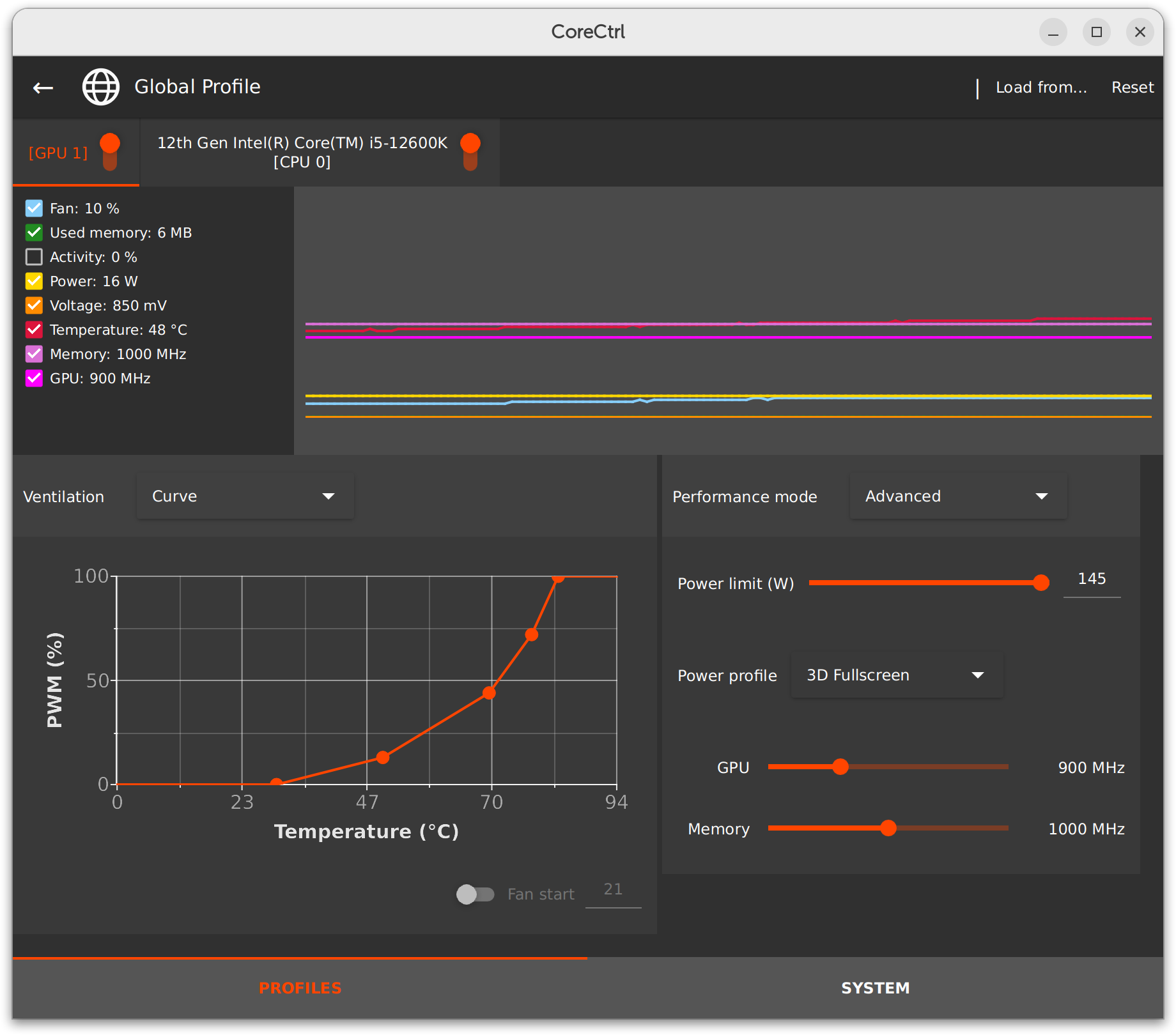
I benchmarked my Photon Mapping engine on two settings: 900Mhz GPU, 1000 MHz VRAM versus: 1360MHz GPU, 1750 MHz VRAM.
I then checked the FPS and the (reported!) Wattage. I guess for a more complete tests, measuring power consumption at the wall socket would have been better. Maybe another time.
So, with the higher clocks, we expect better performance of course. Did we get better performance?
Clocks FPS Volt Watt
900/1000 38 0.850 47
1360/1750 46 1.150 115
The result was even more extreme than I expected: For 145% more power consumption, I got to enjoy 21% more frames/s.
Not only that. The high-clock setting came with a deafening fan noise, whereas I did not hear a thing at low Voltage.
Which now makes me ask the question: Shouldn't those benchmarking youtube channels do their tests differently? Why are we not measuring --deep breath-- frames per second per (joule per second) instead? (As Watt is defined as Joule/Second.)
We can of course simplify those units as frames per joule, as the time units cancel each other out.
Hot take: LTT, JayzTwoCents, GamersNexus should all be benchmarking GPUs at at lower Voltage/Clock setting. I do not care if RTX inches out a Radeon by 4% more FPS at 450Watt. I want to know how they perform with a silent fan, and lowered voltage. Consumer Report tests a car at highway speeds, not on a race track with Nitrogen Oxide and a bolted on Supercharger. We should test GPUs more reasonably.
Can we please have test reports with Frames per Joule? Where is my FPJ at?

UPDATE: I can't believe I missed the stage-4 galaxy brain. We can invert that unit to Joules/Frame instead!


Because I am a sucker for Linux SBCs, I got myself a Sipeed Lichee Pi 4A RISCV SBC. And remarkably, it can do OpenCL too! Which means I can try my Photon-Mapping CL kernel on it.
Even though it can run OpenCL kernels, I did find that the OpenCL implementation is not the most stable one: As soon as I try to fill a buffer with clEnqueueFillBuffer() it will crash.
The performance of my kernel on this SBC was incredibly bad though: three orders of a magnitude slower than a desktop GPU. Which made me wonder what the performance would be on my Raspberry Pi 400.
Eben Upton designed the VideoCore IV GPU in the original rPi. So surely, the software support should be excellent. Sadly, there is no OpenCL for the rPi4.
CLVK to the rescue! This sofware will translate OpenCL kernels to Vulkan compute kernels. Even though RaspberryPi OS would not work with it, Ubuntu 23.04 for rPi would, as it had a newer Mesa.
Which brings us to the next disappointment: even though there is a Vulkan driver for the rPi4, this driver lacks important Vulkan extensions. It cannot handle 16-bit floats, nor can it handle 8-bit ints.
unknown NIR ALU inst: vec1 16 div ssa_217 = b2f16! ssa_182
This leaves us with a rather lacking implementation. Since I wrote my Photon Mapper for FP16, this experiment has to be shelved.

Once again, I find myself porting CUDA code to OpenCL. And I had to remind myself of the process, and the differences between the two. Let's document, so future Bram will catch up quickly again.
The major difference is of course compatibility. OpenCL is supported by Nvidia, Amd, Intel, etc. CUDA is only supported by Nvidia. It's the whole reason of this porting exercise.
The CUDA-kernel can be pre-compiled by the developer using nvcc, and then be shipped as a PTX file. The OpenCL-kernel typically ships as C-like source.
The function definition of a CUDA-kernel gets prefixed with __kernel whereas an OpenCL uses a __global__ prefix.
A CUDA-kernel uses blockIdx and blockDim to determine which sub-part of the input data it is supposed to process. An OpenCL kernel uses get_global_id() instead.
Using 16 bit floating point arithmetic is as easy as #include <cuda_fp16.h> and using __half. On OpenCL you need to check for an extension and add #pragma OPENCL EXTENSION cl_khr_fp16 : enable
In CUDA, constant input data is prefixed with __constant__ which the host then sets with the cuMemcpyHtoDAsync() function after getting the symbol using the cuModuleGetGlobal() function. In OpenCL if the constant input data is large, you prefix it with __global__ and the host sets it with the clCreateBuffer() and clEnqueueWriteBuffer()functions.
Half float literals need a constructor in CUDA: __half(1.0) but can use a suffix in OpenCL, where 1.0h can be used.
Many operators need a function call in CUDA. The reciprocal in CUDA is hrcp(x) and a simple <= on a half float becomes __hlt(a,b) which makes it less legible.
A minor diffence is that CUDA's atomicAdd is atomic_add in OpenCL.
CUDA has asserts but OpenCL does not.

When it comes to video games, I don't think Minecraft has been surpassed. Like all the best games, it has a simple premise: mine blocks in an infinite world, and use them to craft other blocks. But from this simple fundement, a master piece arose.
Even after the purchase by Microsoft, the game is still available for Linux, as Mojang maintains a Java version of their game. Lately, I have been looking into running a server, and intend to write custom code, server-side, to see what can be done with that. Minecraft lets you modify the client code. But this post investigates the modification of the Minecraft server.
Minecraft modding has a long history. But it appears that my best entry point would be SpigotMC.
After executing BuildTools.jar, I ended up with a file called spigot-1.19.3.jar which I copied to my minecraft server root directory. Instead of running minecraft_server.1.19.3.jar I now run the spigot jar file instead.
To make sure newer minecraft clients can connect, you can put ViaVersion.jar in the plugins directory.
Next up, is finding out how to write custom server code. So far I have found Kody Simpson's Youtube series an excellent resource.
Bukkit is a Java Interface, and it is implemented by CraftBukkit.
CraftBukkit is implemented using net.minecraft.server code.
This means that the same object can be referenced and used at three different levels. For instance, the player exists as Bukkit's Player, as CraftBukkit's CraftPlayer and as Mojang's EntityPlayer.
Only the Bukkit interface remains stable between releases, and can be used on different minecraft server versions. Also, the NMS (net.minecraft.server from Mojang) code is decompiled, and obfuscated.
Does coding an NPC require NMS? Or can it be done in SpigotMC? If not, what about PaperMC?
To deal with the obfuscation of n.m.s. there are the so called Mojang mappings. Initially I was unable to use those with Java 19. But using a development version of SpecialSource I was able to use n.m.s. with Java 19.
When getting confused in API terminology, this is a good reminder.
I noticed that using the remapped API, really slowed down my iteration speed. Building my plugin went from a few seconds, to 1 minute, because the remapper is slow.
The first restults from my experiments: The Little Vex That Could. A construction-buddy that builds castles from IKEA flat-packs.