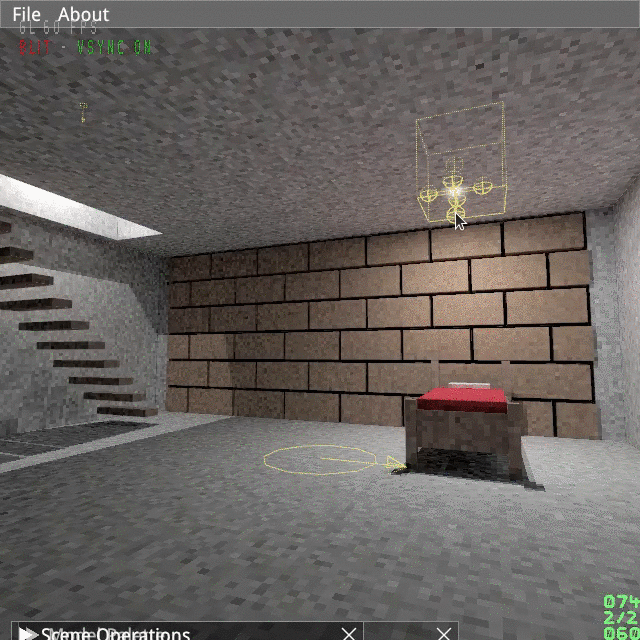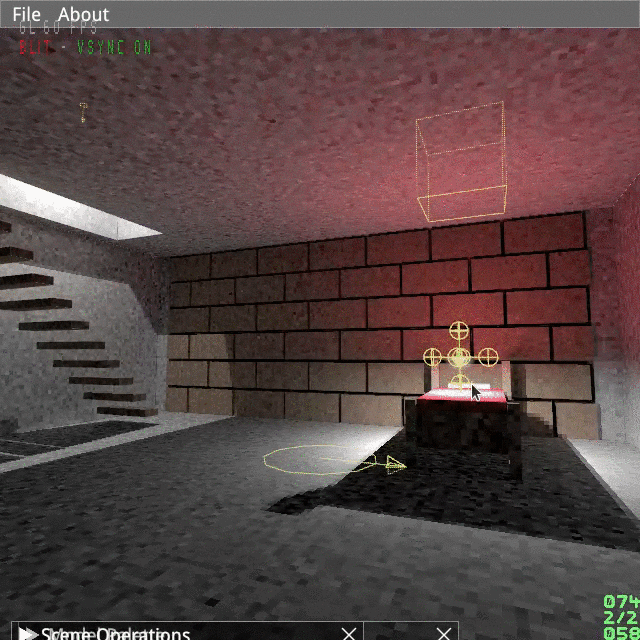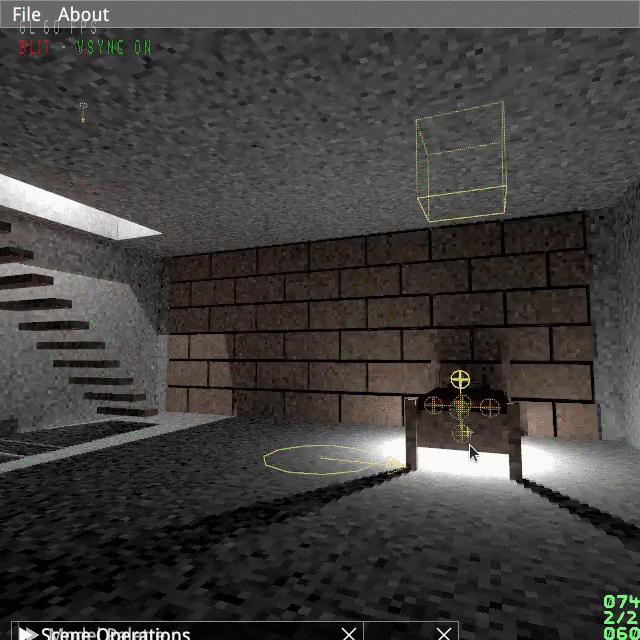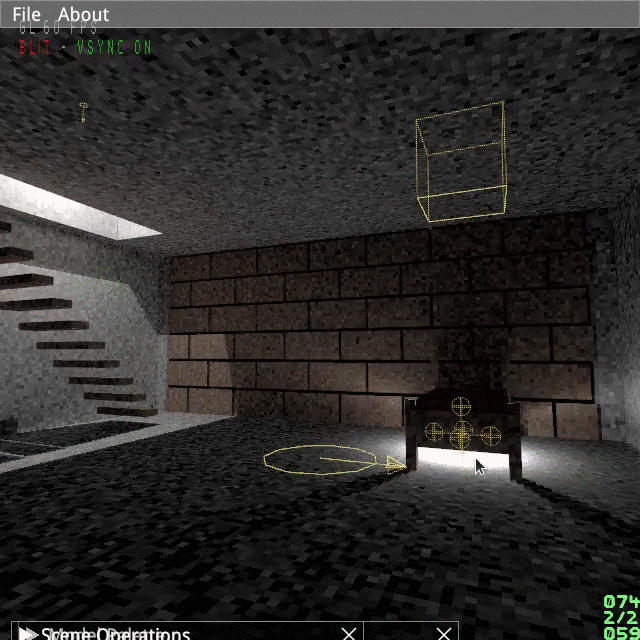
(Just 120 particles, looks better in 60Hz and without GIF artifacts.)
This is a quick 'n dirty approach for getting a fire visualization using OpenGL.
Fire blends somewhat with its background, so we will be using blending.
But unlike regular transparency, fire works a little different: it only adds light to your framebuffer, never removes it.
For this, the blendmode GL_ONE, GL_ONE is perfect!
Ok, now we know how to draw it, which leads to the question, on what to draw.
I find that the majority of approaches you find on the web go for textured billboard.
But I think that it is better to go with geometry instead, that is un-textured.
By adding some shape to the geometry that you draw, you can save on the number of particles you need to draw.
I opted for a spikey kind of vortex, as shown below.
From the picture above you can see there is already an inherent counter-clockwise rotation in the model, which we should replicate in the animation.
So as we draw each particle, we should keep rotating the billboard we draw for it.
Of course, the billboard needs to be oriented to the camera as well!
Which means we have to do a little math in the vertex shader.
#version 150
in mediump vec4 position; // per vert: vertex position.
in mediump vec4 bdpos; // per inst: bill board pos.
in mediump vec4 rgb; // per inst: colour.
in mediump float scale; // per inst: scale.
in mediump float angle; // per inst: angle.
out lowp vec3 colour; // to fragment shader: colour.
uniform highp mat4 modelcamviewprojmat;
uniform highp mat4 camtrf;
void main()
{
vec4 camx = camtrf[0];
vec4 campos = camtrf[3];
highp vec4 scaledpos;
scaledpos.xyz = position.xyz * scale;
scaledpos.w = 1.0;
vec3 z = bdpos.xyz - campos.xyz;
z = normalize(z);
vec3 camy = camtrf[1].xyz;
vec3 xx = cross( camy, z );
vec3 yy = cross( xx, z );
vec3 x = xx * cos(angle) + yy * sin(angle);
vec3 y = xx * -sin(angle) + yy * cos(angle);
mat4 trf = mat4(1.0);
trf[0].xyz = x;
trf[1].xyz = y;
trf[2].xyz = z;
trf[3] = bdpos;
highp vec4 tpos = trf * scaledpos;
colour = rgb.rgb;
gl_Position = modelcamviewprojmat * tpos;
}
Let us break down that vertex shader.
Like any vertex shader for 3D graphics, it transforms a vertex (position) using a modelviewprojection matrix, no surprised there.
All the other inputs for this shader are per-instance attributes, not per-vertex attributes.
So you need to call glVertexAttribDivisor() for them, with value 1.
Every particle billboard has a position (bdpos,) a colour (rgb,) a size (scale,) and a rotation (angle.)
The scale we just apply to the model's vertex position before we transform the vertex to clip-space.
And the colour is passed onto the fragment shader, as-is.
Note that we don't just pass the modelviewprojection matrix, but also a second matrix: the camera transformation.
This is just the view matrix, before it got inverted from camera to view.
We need this, so that we can reconstruct a proper orientation for our billboard.
We create a model transform for the billboard with Z pointing to our camera.
This is basically (xx,yy,z, bdpos). But we skew the xx,yy axes with the particle's rotation angle, so that we end up with the (x,y,z, bdpos) transform.
To skew them, the new x,y are both just a linear combination of the old xx,yy with the cos/sin factors.
Once we applied, this per-particle transformation to the (scaled) vertex position, we get our transformed position (tpos.)
That, can finally be transformed with the modelviewproj matrix to give us our final result.
That covers the GPU-side of things. But we still need to fill in the proper rgb/scale/angle values on the CPU-side.
The scale is easy: because gas disperses as it burns, we just have to make the particle grow in size, as it ages.
The angle is easy too, I just apply a rotational velocity that scales with the linear velocity of the particle, always in the same direction (counter clockwise.)
That leaves us with the colours.
We use GL_ONE, GL_ONE, and it is best to use low colour values, so that sharp boundaries between particle and no particle are not too obvious.
Also, we should slowly fade-out our particles.
So as the particle ages, I make it go fainter!
And for the chromatic transitions, just make the particle go from whitish, to yellowish to reddish, and you should be good.
I am using this approach in my project for Real Time Global Illumination, where I use the particles as light sources.